While reasoning on some ML concepts I just stumbled on an interesting question, who and what is providing fast low level APIs, for example for computing matmul etc?
The answer happened to lie in the BLAS interface definition, the Basic Linear Algebra Subprograms. BLAS defines a standard set of routines for common linear-algebra operations, while libraries such as Apple Accelerate, Intel oneMKL, OpenBLAS, cuBLAS,and BLIS provide optimized implementations. Netlib also provides reference implementations, which prioritize portability and correctness rather than peak performance. As you can see hardware vendors usually ship also their BLAS implementation taylored for the hardware.
BLAS was originally specified through Fortran routines. C programs can call the same operations through CBLAS, a C interface with conventions that are more natural in C, such as explicit row-major and column-major layouts.
High-level machine-learning frameworks rely heavily on operations such as matrix multiplication. Their performance depends on optimized numerical kernels supplied by the framework, hardware vendor, or an external library. These notes grew out of studying BLAS and the roofline model, with the practical goal of writing a custom SGEMM kernel and comparing it with Apple Accelerate's cblas_sgemm.
The complete implementation used in this article is available in the custom-blas repository.
Operations offered by BLAS
BLAS routines are divided into three levels. For dense square inputs of dimension , their characteristic computational costs are:
| Level | Main operation | Example | Computational cost |
|---|---|---|---|
| 1 | Vector-vector | AXPY | |
| 2 | Matrix-vector | GEMV | |
| 3 | Matrix-matrix | GEMM |
I am mainly interested in the third category: matrix-matrix multiplication. The conventional algorithm has a time complexity of . Asymptotically faster algorithms exist: Strassen's algorithm, for example, runs in . In practice, conventional blocked GEMM is usually preferred for ordinary matrix sizes because it has smaller constants, better numerical properties, and maps efficiently to modern memory hierarchies. Some libraries use Strassen-like methods selectively for sufficiently large matrices.
BLAS routine names encode the data type and operation. Common precision prefixes are:
| Prefix | Data type |
|---|---|
S | Single-precision real (float) |
D | Double-precision real (double) |
C | Single-precision complex |
Z | Double-precision complex |
Many matrix routines then include a code describing the matrix structure and operation:
| Code | Meaning |
|---|---|
GE | General matrix |
SY | Symmetric matrix |
TR | Triangular matrix |
GB | General band matrix |
MV | Matrix-vector operation |
MM | Matrix-matrix operation |
For example, SGEMM means single-precision general matrix-matrix multiplication.
The Netlib documentation describes both the cblas_sgemm and Fortran SGEMM interfaces.
Roofline model
The roofline model helps determine whether a kernel is limited by compute throughput or memory bandwidth. It uses the following quantities, that we can define:
- Work, : the number of floating-point operations performed, measured in FLOPs.
- Memory traffic, : the number of bytes transferred between the relevant levels of the memory hierarchy.
- Arithmetic intensity, : the ratio , measured in FLOPs per byte.
- Performance, : the achieved rate of computation, measured in FLOP/s.
For a given architecture, let be its peak floating-point throughput and its peak memory bandwidth. The roofline bound is
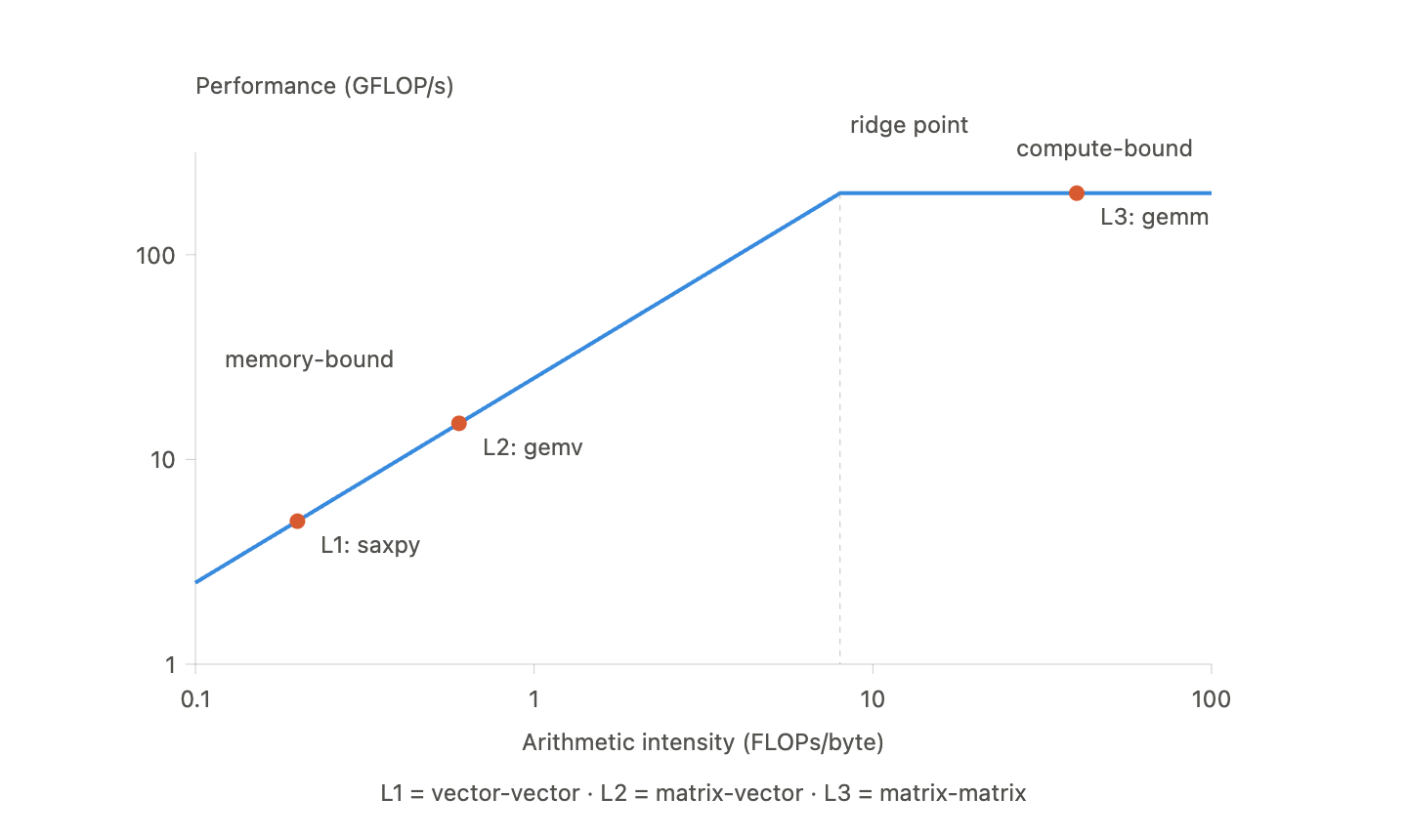
The intersection between the horizontal compute roof and the diagonal bandwidth roof is the ridge point:
Kernels to the left of this point are bandwidth-bound under the model; kernels to the right are compute-bound.
For an AXPY-like vector operation, both the work and memory traffic scale as , so arithmetic intensity remains . Dense matrix-vector multiplication performs work but must also read matrix elements, so its intensity is also .
Dense matrix-matrix multiplication performs work on input and output data. With a blocked implementation that reuses data effectively, its arithmetic intensity can grow as . This reuse is why GEMM can move into the compute-bound region. A naive loop nest does not automatically achieve the minimum possible memory traffic, so its realized intensity may be much lower.
Writing SGEMM from scratch
The goal is to implement several simplified SGEMM variants and compare them with Apple Accelerate:
- Naive
i-j-kloop order - Reorganized
i-k-jloop order with vectorization disabled - Reorganized
i-k-jloop order with vectorization enabled
The standard CBLAS signature is:
void cblas_sgemm(
CBLAS_ORDER Order,
CBLAS_TRANSPOSE TransA,
CBLAS_TRANSPOSE TransB,
int M,
int N,
int K,
float alpha,
const float *A,
int lda,
const float *B,
int ldb,
float beta,
float *C,
int ldc
);It computes
The parameters have the following roles:
Orderselects row-major or column-major storage. C supports both; this experiment usesCblasRowMajor.TransAandTransBspecify whether each input is used as-is or transposed.M,N, andKdefine the matrix dimensions: is , is , and is when neither input is transposed.alphascales C$.lda,ldb, andldcare the leading dimensions. For contiguous row-major matrices without padding, they are respectivelyK,N, andNin the non-transposed case.
A × B = C
(M × K) (K × N) (M × N)To keep the experiment focused, every custom implementation supports only square, row-major, non-transposed matrices and is called with and :
cblas_sgemm(
CblasRowMajor, CblasNoTrans, CblasNoTrans,
n, n, n,
1.0f,
A, n,
B, n,
0.0f,
C, n
);The custom functions mimic the CBLAS parameter list but do not implement the complete cblas_sgemm contract.
Naive version
The naive implementation computes the dot product between each row of and each column of :
for (size_t i = 0; i < N; i++) {
for (size_t j = 0; j < N; j++) {
float acc = 0.0f;
for (size_t k = 0; k < N; k++) {
acc += *(A + lda * i + k) * *(B + ldb * k + j);
}
*(C + ldc * i + j) = acc;
}
}The accesses to are contiguous, but the accesses to use a stride of ldb. This is inefficient for row-major storage because consecutive iterations touch different rows of .leading to cache misses, that are very costly.
Reorganized version
Changing the loop order from i-j-k to i-k-j makes the innermost loop traverse rows of and contiguously:
for (size_t i = 0; i < N; i++) {
for (size_t k = 0; k < N; k++) {
float a_i_k = *(A + lda * i + k);
for (size_t j = 0; j < N; j++) {
*(C + ldc * i + j) += a_i_k * *(B + ldb * k + j);
}
}
}Because this version accumulates into , the benchmark initializes to zero before each run. The measured scalar variant also explicitly disables Clang's loop vectorization and unrolling, isolating the effect of loop reordering as far as this compiler configuration allows.
Vectorized version
The final custom variant keeps the same memory-access pattern and asks Clang to vectorize and interleave the inner loop:
for (size_t i = 0; i < N; i++) {
for (size_t k = 0; k < N; k++) {
float a_i_k = *(A + lda * i + k);
#pragma clang loop vectorize(enable) interleave(enable)
for (size_t j = 0; j < N; j++) {
*(C + ldc * i + j) += a_i_k * *(B + ldb * k + j);
}
}
}On the Apple M2, NEON vector registers are 128 bits wide, so one vector can hold four 32-bit floats. This makes the loop suitable for SIMD, although register width alone does not predict the complete speedup: instruction scheduling, fused multiply-add throughput, memory traffic, and compiler decisions also matter.
Results
The benchmark produced the following results on an Apple M2:
| Implementation | ||
|---|---|---|
Naive (i-j-k) | 1.72 GFLOP/s | 0.92 GFLOP/s |
Reorganized, scalar (i-k-j, no auto-vectorization) | 6.37 GFLOP/s | 6.38 GFLOP/s |
Reorganized and vectorized (i-k-j, SIMD) | 27.33 GFLOP/s | 26.54 GFLOP/s |
Accelerate cblas_sgemm | 789.81 GFLOP/s | 1035.06 GFLOP/s |
At , loop reordering improves performance from 1.72 to 6.37 GFLOP/s, a gain of approximately . The main difference is the access pattern: the naive version reads column by column with stride ldb, whereas the reorganized version accesses and sequentially in the inner loop.
Enabling vectorization raises performance from 6.37 to 27.33 GFLOP/s, approximately another . This is consistent with SIMD being effective on the contiguous inner loop, but it should not be interpreted as proof that the speedup comes exclusively from processing four floats per vector instruction.
The total improvement from the naive to the vectorized custom version is approximately . Accelerate remains much faster: about faster at and faster at .
This remaining gap cannot be closed by a vectorization pragma alone. High-performance GEMM implementations typically combine several techniques:
- Cache blocking: partitioning matrices into tiles so that data is reused while it remains in a nearby cache.
- Register blocking and microkernels: keeping a small output tile in registers across many multiply-add operations.
- Parallelism and architecture-specific kernels: distributing work across cores and using instructions or matrix hardware tailored to the processor.
Conclusion
BLAS routines are fundamental building blocks for scientific computing and machine learning. This experiment shows that two understandable changes—improving memory access and enabling SIMD—can produce a substantial speedup, while also demonstrating how much additional engineering separates a simple loop nest from a production GEMM implementation.
The next step is to add cache blocking and a register-level microkernel, then evaluate them with a more rigorous benchmark harness.